Written by —

I claim that a data platform built with sustainability is more secure, affordable and maintainable than the competition. Together with the Green Coding initiative and usage of SaaS and cloud resources, one can start the journey of building a more sustainable data platform. In this article, I'll list sustainable activities that any Data Architect, Data Engineer or data professional can make in their daily work.
Written by —
This is a continuation of my previous blog where I claimed that a data platform built with sustainability is more secure, affordable and maintainable than the competition. In the first part, I went through the background of current sustainable, green coding and ICT actions. I also introduced the first action that Data Architects and Data Engineers can implement in their daily work, SaaS -services. Besides SaaS -delivery, one should also consider the following actions.
Common services over separate entities
As data has become a more valuable asset for companies, we've seen multiple companies developing their data platforms. These projects are driven usually by one business unit for their purposes. One business unit might start developing a data platform to obtain better visibility on business unit specific sales. The data platform performs well and gains attraction within the company so much that second business units want that similar visibility on their sales. Instead of leveraging the already existing data platform, they decide to invest in their platforms. This pattern is tempting because it gives freedom to work on your terms. This pattern also doubles the need for source system integrations, target databases and data pipelines. The results of these data platforms might also create competitive views on key figures making it hard to determine the actual truth.
I'm not stating that an enterprise-level data warehouse is the 'right' way for all, but meeting halfway would benefit all parties. I say that if you are on the verge of building a data platform for your needs, investigate first whether you can leverage any existing data platform for your needs. Creating integrations, for example, is a time-consuming job that you usually want to do only once.
If you can't leverage the existing data platform, consider at least the following list of actions.
- Use the already chosen cloud vendor and the same region
Building into the same cloud and region where existing work has been done helps you in future if you want to transfer or share data between platforms. Data transfers between the same cloud and region are far easier, faster to do and by so, less resource consuming.
- Use the already chosen data platform target database installation
If you build a data platform to leverage the same target database account or instance, albeit, with a different schema, you increase enormously your data sharing capabilities. You are also easing your user access management tasks. User access management which sounds trivial is an often task that takes time. If someone else has thought of the correct roles and groups to use, you should utilise those. Leveraging the same database installation also minimises the security area which you are exposing. It's easier to have one secure database than several. All in all, one database installation limits the number of physical servers needed to host your data.
- Use the already chosen integration tools
As said earlier, creating integration from a source system to a data platform is a time-consuming job that no one wants to repeat. If someone has built an integration that writes the data from the source system to a data lake in a readable format, try to tap into the same data lake. This pattern will minimise the workload made to the source system and more importantly, will lessen the amount of duplicated data.
Scalable and containerized architecture
Kubernetes was created by Google to tackle long build times, slow development cycles, poor resilience on failures and low resource utilisation. Whether ETL or integration pipeline, one should build the data architecture pipeline leveraging microservices running on containers instead of using virtual machines that are always on. These microservices should contain only the necessary code for that pipeline and be used only when needed. Together with, for example, the usage of Kubernetes, one can create a data platform where most of your data pipeline components do reside in a platform that will
- handle failures i.e. restart your services
- tackle most of your security issues by forcing you to code minimal microservices
- be faster to develop due to the nature of independent microservices
- be utilised more efficiently i.e. being more sustainable
Scalability should be applied to other data resources as well. The database is the most resource-consuming service of your data platform. The database should follow the same principles as your database pipelines. It should handle failures, be secure and be utilised as efficiently as possible. In database technology, this means the separation of computing and storage.
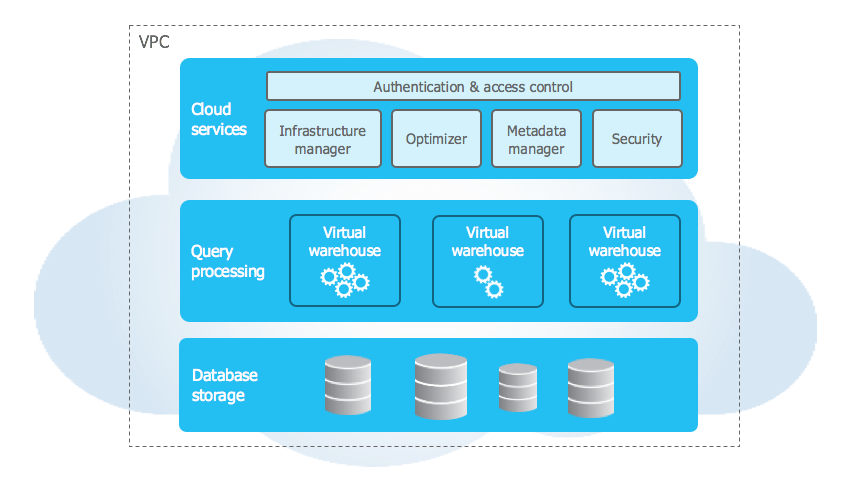 Separation of computing and Storage as per Snowflake - Snowflake.com
Separation of computing and Storage as per Snowflake - Snowflake.com
Efficient code and coding language
If you have browsed the web, you might have come across a study that shows that Python is a slow language, meaning it takes a lot of time to execute. When you consider that the more time you spend on execution, the more energy you consume. For instance, C, C++ and Java outrank Python almost 70 to 1 in energy efficiency. Python is also the favoured language used in data platforms due to its easy learning curve.
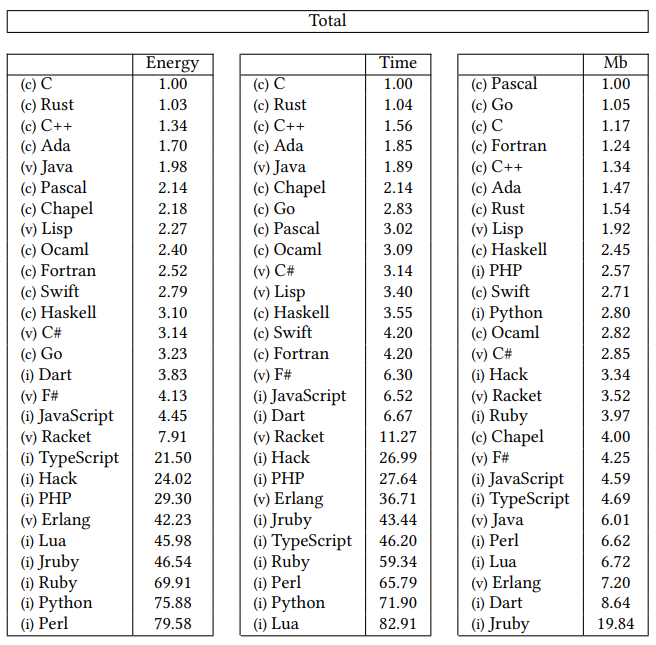 Energy Efficiency across Programming Languages - Pereira, Cunha, Couto, Fernandes, Rui Rua, Savaira
Energy Efficiency across Programming Languages - Pereira, Cunha, Couto, Fernandes, Rui Rua, Savaira
I'm not proposing ditching Python in data platforms and using C. Instead I'm proposing to investigate code pieces that consume time because those could be candidates for code refactoring or language change. Code refactoring or language change would most likely lower your costs when using Serverless Functions (AWS Lambda, Azure Functions) because your code would execute in a faster time and on a consumption-based plan, lower your costs.
There is the curveball of serverless cold-start times that add another layer for choosing the best language, but overall the concept is the same. Follow the rules that Microsoft also proposes: "Sometimes the answer is simply writing more efficient code... Along this vein, try to minimise the amount of work that has to happen before your code starts up and avoid code which consumes a lot of CPU. ".
Writing code that is faster and more efficient means also more secure code. The fewer dependencies on foreign libraries you use, the less code you have that might be vulnerable to security hacks (case Log4j).
Python is not the most used language in data platforms. We write SQL, and bad SQL can consume unnecessary resources. Because we want to use databases that offer scalable resources, we want to write SQL that does execute well. Scalable computing does not mean that it is ok to write SQL that does full-table scans. If you see SQL queries that take a lot of time, take a second to investigate the root cause. Eventually, you will save money and also your data pipeline will execute faster, making everybody in your team happier.
The whole list is as follows
- Favour SaaS services over PaaS and self-hosted installations
- Favour architecture that embraces common services over separate entities
- Favour scalable and containerized architecture
- Favour efficient code and coding language
Immediate actions from right now
If the previous actions are not something that you can implement right now, but you would like to make concrete actions right now, you should look into your data platform and find out whether you have services or virtual machines underused. These services can automatically be set to shut down during the night and at weekends preserving energy usage and costs. If you can also make changes to the underlying servers, consider changing for the existing virtual machines to use ARM64 -architecture which is now on the public preview on Azure and AWS. ARM64 -based virtual machines provide up to 50 per cent better price-performance than comparable x86-based virtual machines (VMs) for scale-out workloads. With ARM64 -based servers you will preserve energy and save money at the same time.
You can also start demanding better remote work guidelines and tools. Working remotely is an action that will lessen the CO2 emissions from day one. Although remote work has been part of our lives for a time, proper guidelines and tools might not be in place in every company. Meeting rooms at customer premises might be outdated, having video conference systems that work but sound awful for the hearer. Information sharing on projects where part of the people are at the office and part developing remotely. These obstacles can and should be fixed because they will help your project to become a success and lessen the need to travel to the office leading your project to be more sustainable.
Closing words
As one can see, building sustainable data platforms or solutions is already here. The need for sustainability will eventually trickle down from data products into the code itself and you can be at the frontline of sustainable data business starting today. As your business needs increase, the need for SaaS -products will increase as you want to focus your time on actual work, not maintaining the infrastructure. I see that companies that are following this list of actions are succeeding already now.
If you want to have help in choosing the best fit-for-purpose SaaS data products, we are here to help you. For modern work, our sister company together with Karoliina can happily help you.
Enjoyed the article? You should then consider working with us! We are constantly looking for Data Engineer and Data Architects to join our kick-ass bunch of data troops! Read more about us and apply👇




