Written by —

Written by —
dbt v1.0.0. is out!! :PARTY:
The first thing you’ll probably notice is the division dbt-core and the different adapters. There’s no more “pip install dbt”; it’s now adapter specific “pip install dbt-snowflake” or “pip install dbt-postgres” for example. All of the adapter specific packages are built on top of dbt-core, so you’ll see that installing as well.
This renaming also takes place in the Git repositories: dbt-core repo is the dbt you know, and adapters have their own repositories, with their own issue trackers. This with some other housekeeping in the dbt-labs Git will hopefully make it more accessible. Following the issues and discussions has been some work lately.
So what does 1.0.0 actually mean? We’ll, dbt now finally has a major version out. This means that there will no longer be any breaking changes between minor versions. dbt has been production ready for some time even though it has been 0.1x or something for a long time. Now, you can trust that while updating between 1.x versions you shouldn’t have any surprises. This also extends to adapters: database specific adapters should get patches much more rapidly from dbt-core now that the adapter interface is declared stable.
New features in 1.0.0
Running “dbt init” is now interactive. Running it in a new project is perhaps not that an interesting change, but what is interesting is that you can define your own template for running init in an existing project! This way you can easily help your new team members to get that project specific profile.yml up and running!
performance
Release notes promise a 100x faster experience compared to v0.19.0. If this holds true, it is truly a welcome improvement for larger projects. I don’t know if it truly is 100x, but 1.0.0 does feel fast.
Events and logs have been reworked. While this might not seem that special from just dbt point of view, reworked events lay the foundation for real-time integrations. And as dbt is just one tool in your arsenal for analytics engineering, this will surely be a welcome change.
Perhaps the most familiar looking new feature is the new Metrics feature. An interesting opening towards “Headless BI”; scalable, automated and UI independent analytics. Much like Exposures (Don’t know what they are? You really should be using them), Metrics provide definitions for downstream tools to actually generate metrics, provides a consistent and version controlled place for their definitions, and a nice selection method for running metric related models in a DAG. Read much more about the Metrics-feature at https://github.com/dbt-labs/dbt-core/issues/4071. This will surely be an interesting new feature, and providing useful tools for headless BI is really required. I’ll be anxiously waiting to see more from this feature. Documentation is at https://docs.getdbt.com/docs/building-a-dbt-project/metrics.
Other recent big features
Some other recent features that really shine in production usage are: “on schema change” configuration for incremental models; the “dbt build” command; and “Slim CI” and the concept of state.
One strife I’ve had with dbt has been it’s take on schema changes on incremental models. It was basically “no”. Always creating new tables or using snapshots had their own problems, and doing a --full-refresh just to add new columns was cumbersome. Introduced in v0.21.0, there’s now an “on_schema_change” configuration for updating incremental models! Finally! There’s a few configuration options on what dbt should, or shouldn’t, do on schema changes on incremental models when full-refresh is not defined. Do note that this will not backfill those new columns. For that, a full-refresh is required.
dbt build is a new command also introduced in v0.21. Basically it does everything in the DAG: run models, tests, snapshots and seeds. Again, finally! This greatly simplifies running dbt in production environments as you don’t have to build your DAG with “run seeds, run staging, test staging, run transformations, test transformations, run publish, test publish, swap publish” or similar patterns. Just a simple “dbt build” with possible selectors is enough.
Related to the above note of running dbt in production environments, is the concept of “state”. Introduced in v0.18, “state” in dbt means two things: the artifacts dbt produces, and run results. This allows for example running only the modified models/tests, and only the parts that previously failed. Much more about state and what you can do with it in: https://docs.getdbt.com/docs/guides/understanding-state and https://docs.getdbt.com/docs/guides/best-practices#run-only-modified-models-to-test-changes-slim-ci
coalesce 2021 updates
Coalesce, “The Analytics Engineering Conference”, a virtual conference with topics about and around the data build tool was held on December 6-10. Here are some picks from the Coalesce.
Right out of the gate, Databricks announced a dbt-databricks adapter! Dbt-databricks is supported by the Databricks people, and can be found at: https://github.com/databricks/dbt-databricks. This is a great direction in my opinion, where the target system developers take responsibility of the dbt adapter development (compared to dbt-snowflake or the old dbt-spark for example, which while open source, is under dbt-labs). While dbt only works on SQL, this surely is a compelling tooling for building Data Lakehouse and that delta lake layer. Unlike dbt-spark, dbt-databricks doesn’t depend on ODBC, so it really streamlines the installation and setup hassle. dbt-databricks is built on dbt-spark. Yay for the open source community! More info at https://databricks.com/blog/2021/12/06/deploying-dbt-on-databricks-just-got-even-simpler.html
Like dbt-databricks, there’s now dbt-firebolt for the latest generation in Cloud Data Warehouses! https://github.com/firebolt-db/dbt-firebolt Like dbt-databricks, this is a Firebolt maintained adapter. Some features are still missing, but based on Firebolt’s session, they are really putting in the effort on this one.
Another great presentation was about dbt project maturity aptly titled “Building a Mature dbt Project from Scratch”, by Dave Connors from dbt Labs. In his presentation, Dave had two points of view on maturity: Feature Completeness: “breadth of things you can make your project do”; and Feature Depth: “the level of sophistication and quality within the use of individual features”.
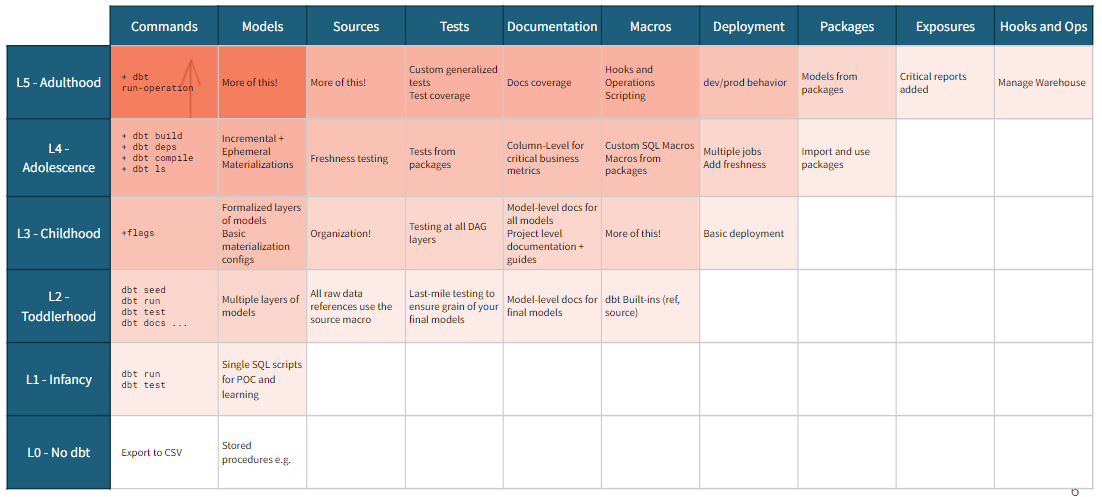
Here we have a matrix with the two dimensions, and some feature implementations which are most valuable at the different maturity levels. It provides a good comparison tool for your project: where do you think you are? What are you doing? What should you do next to fully take advantage of all of your possibilities? The implementation of some of these cells could be a topic for another time.
Then there’s the upcoming updates on dbt server! Drew Banin, of dbt labs, presented the Metrics functionality, and how it makes Headless BI a possibility. What he also teased was how the dbt server, the old dbt-rpc, is going to support this by generating the metrics SQL on the fly for the actual BI interfaces! This is going to be huge! They are now in closed beta, and the full launch should be in 2022.
The v1.0.0 really brings some interesting new openings to the whole dbt system: Metrics together with the existing Meta tags and Exposures, and the reworked Events and upcoming dbt server build an exciting foundation for Headless BI: Automation and true scaling in-place of multiple manual UIs.
Want to learn more about dbt? Check my previous blog post about our previous Hackathon about dbt at: https://www.recordlydata.com/blog/the-recordly-hackathon-learning-about-dbt. And we are constantly recruiting new people to join us on new data projects, with and without dbt.




